
Recently, there has been an increase in the need for an automated sentiment analysis model among businesses, especially within e-commerce. Currently, there are many pre-trained models available to be quickly applied. However, they are often not completely free nor do they support Swedish language yet - such as Natural Language API by Google. Or they do have Swedish options available, like vaderSentiment for Swedish language module, but does not work well and fails the tests from our critical "judges" here at Hello Ebbot.
At Hello Ebbot we would like sentiment analysis functionality for our chatbots. Therefore we decided to train a model ourselves. It will surely take us more time to collect data, train, then deploy the model into production - that is not a problem however, as we want our products to offer not just conversational virtual assistants, but ones that are able to think a little. If you're curious about how we can accomplish a model with 75% average accuracy as well as detect sarcastic comments, continue reading to know our secrets.
Sentiment analysis and the problems it solves:
There are many research papers and articles explaining sentiment analysis using professional business or machine learning terms. If you're looking for a complete guide to sentiment analysis, we recommend checking out this blog from MonkeyLearn. But here is a sweet and simple summary for you: sentiment analysis is a technique for processing text data to classify the different emotions (positive, neutral or negative) the text reflects.

Using this automated model, we aim to have Ebbot reply with tonality based on the customers emotions. For example, when customers are angry, Ebbot would sense the negativity in the message and give a comforting answer. Moreover, for Business-to-consumer (B2C) companies, feedback on customer service or product reviews can be collected and analyzed by Ebbot. The solutions we have in mind are currently not available, but we are hoping to bring them into the application as soon as possible.
The development process
In this section, we reveal the technical background of the model. There are a few machine learning terms upcoming, so if you only want to see how the model behaves, you can jump right into this section instead.
We first started by collecting data from Trustpilot using BeautifulSoup web scraping library. Our dataset included reviews for several famous companies in Sweden, such as Telia and Qliro. Because sentiment classifier is basically just a supervised learning task (Datacamp 2020 ), we labeled the reviews based on the number of stars each review had been given. Specifically, five stars were considered "positive", three as "neutral" and one star reviews were marked as "negative".
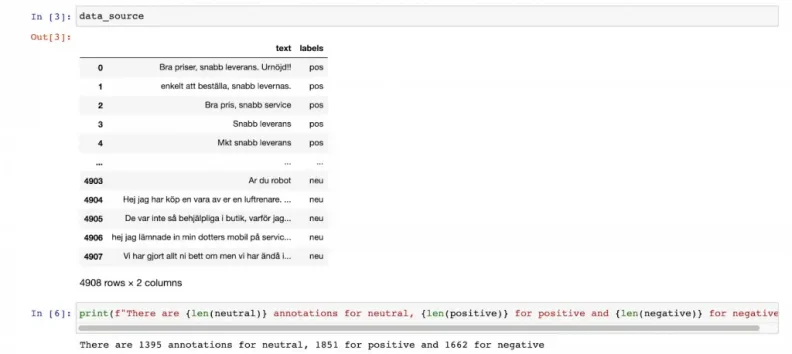
Next step was to decide which classifier we would use for this task. Initially we implemented NLTK's Multinomial Naive Bayes classifier and got amazing results for positive/negative analysis. Our model reached 92% accuracy and was able to detect some false- positive comments.
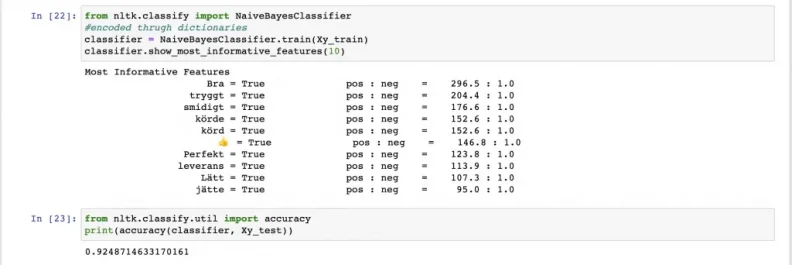
As it turned out, the Naive Bayes (NB) model did not perform well when neutral sentiment came into the picture. In fact, DatumBox did thorough research with some classifiers and concluded that NB gave high accuracy for binary prediction (positive and negative) but much lower for 3-class output (positive, negative and neutral).
That was when sklearn's Support Vector Machine classifier (SVC) came to save the day! Inspired by a project from a fellow machine learning enthusiast using IMDB review and LinearSVC pipeline, we also used K-Fold cross-validator to split data in train/test sets. We divided our dataset into 10 consecutive folds instead of the default five. Among ten folds, the highest accuracy one was 95% and on average, our model gave correct prediction on test sets 75% of the time.
Here are a few ambiguous and/or sarcastic comments that our model surprisingly was able to analyze:
"Tack för att ni är sämst i världen, ni gör det lätt att byta till en konkurrent" → Negative (Thank you for being the worst in the world, you make it easy to switch to a competitor)
"Tack för ingenting" → Negative (Thanks for nothing)
"Jag gillar er produkt men ni är fantastiskt dåliga på kundservice" → Negative (I like your product but you are fantastically bad at customer service)
"Mitt sociala liv är förstört nu för att datorn jag fick av er var över förväntan!" → Positive (My social life is ruined because the computer I got was better than I expected!)
What the "judges" from Ebbot say:
After one month and a half, the model was finally ready for testing! We tried and challenged the model with various types of comments popped up in our head and here are some feedbacks from team Ebbot:
"I thought myself clever and challenged the algorithm with very tricky and ambiguous sentences --but after a number of tries was amazed by how hard it was to fool it." - Oliver
"I have tried alot of sentiment models before but this is the first one that made me think 'Wow, this actually works!'. It’s just super cool and super useful!" - Anders
"The accuracy has been around 75% so far. Impressive stuff!" - Gustav
Even though the results were better than our expectation, we still want to point out some of the limitations of the model. First of all, the average accuracy is only 75% so some of the comments sending mixed signals or are too challenging, will make the model confused. Also worth mentioning that the model only works on Swedish language, therefore only applicable for chatbots that "speak" Swedish.
All in all, this is an exciting step in the right direction. The implications of what this can do for customer service are very promising. And we're looking forward to creating practical applications for the model.
