
After one month of preparing the dataset and training, we proudly present to you a T5 (Text-To-Text Transfer Transfromer) based model that paraphrases any questions in the Swedish language. You might recall that we already developed a similar model, S-BERT, in the past. However, using T5 is completely different compared to our previous approach. Because questions are generated by the model T5 itself, while S-BERT only works as a ”tool” to find similar questions written by humans. By learning from paraphrased questions by the Swedish T5, we are no longer limited to just the topics in our current questions database.
What is T5?
T5 was first presented in the paper Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. It is an encoder-decoder model that is pre-trained on a multi-task mixture of unsupervised and supervised tasks, for which each task is converted into a text-to-text format. T5 is able to perform a variety of tasks such as translation, summarization and paraphrase generation. Currently there are many pre-trained models available, which you can use directly or fine-tune for your specific tasks.
Implementation - Step 1: Translating the dataset to Swedish
In order to train a T5 model for Conditional Generation, we need the Quora duplicate questions dataset. Unfortunately there is currently no available dataset in Swedish, we decided to use the translation model from the University of Helsinki to write a Python script and translate the dataset from English to Swedish. The entire translation process took around five days for both training and validating dataset with a total of 298 528 sentences.
Implementation - Step 2: Training T5 to paraphrase questions in Swedish
Thanks to Ramsri, a Data Scientist from India and his detailed tutorial, we were able to learn from the his training script and work on our own T5 paraphrase model for Swedish language. We used Google Colab and utilized their resources including high RAM and GPU to optimize the training time. Therefore, it only took us one day to complete the training process.Thanks to Ramsri, a Data Scientist from India and his detailed tutorial we were able to learn from the his training script and work on our own T5 paraphrase model for Swedish language. We used Google Colab and utilized their resources including high RAM and GPU to optimize the training time. Therefore, it only took us one day to complete the training process.Thanks to Ramsri, a Data Scientist from India and his detailed tutorial we were able to learn from the his training script and work on our own T5 paraphrase model for Swedish language. We used Google Colab and utilized their resources including high RAM and GPU to optimize the training time. Therefore, it only took us one day to complete the training process.Thanks to Ramsri, a Data Scientist from India and his detailed tutorial, we were able to learn from the his training script and work on our own T5 paraphrase model for Swedish language. We used Google Colab and utilized their resources including high RAM and GPU to optimize the training time. Therefore, it only took us one day to complete the training process.
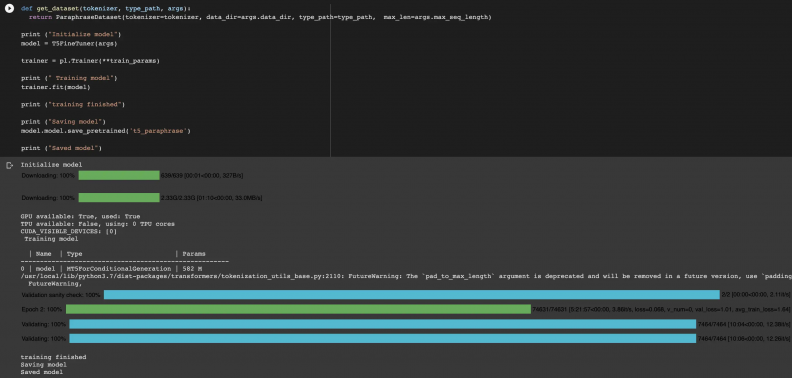
Using Swedish T5 to paraphrase questions
Enough of the boring technicalities, now let’s show you some examples of the model’s performance. Please note that the phrases are generated by the model itself, so there might be grammatical mistakes or random word combinations in some of the sentences 👀
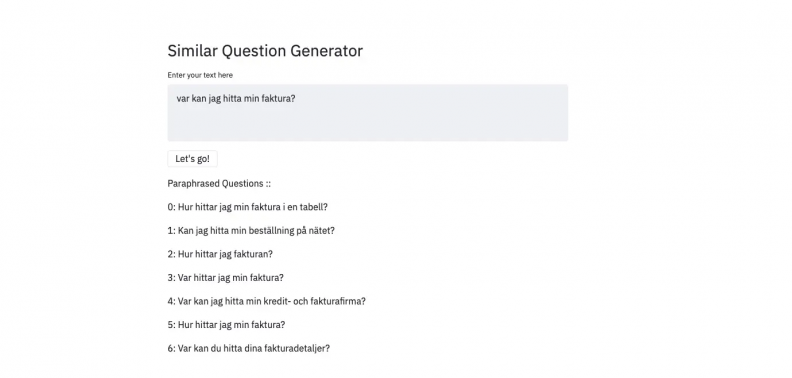
Example 1: The question translated to "Where can I see my invoice?"
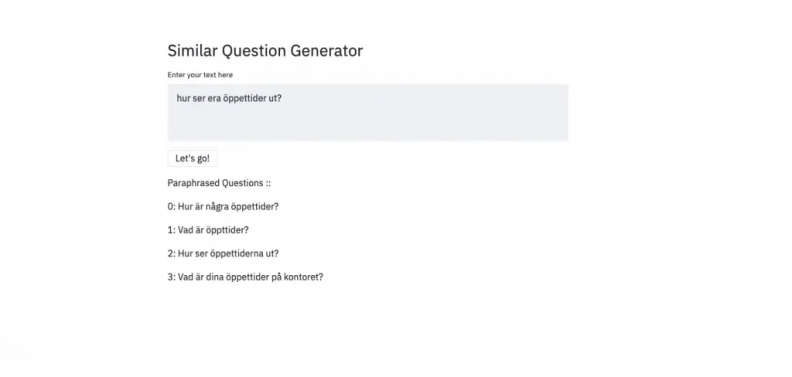
Example 2: The question translated to "What does your opening hour look like?"
Even though the performance of this model is not absolutely mind-blowing and still having grammatical errors as well as troubles with word orders, we can still learn from the sentences that it generates and have a wider variety of example phrases when training a chatbot. Nevertheless, we are hoping to incorporate T5 with S-BERT in order to help the Customer Implementation Team and our customers, to save more time through providing support during the training process.

-(1)-thumb.png)