
The field of natural language processing (NLP) has grown in the past few years with an incredible speed. State-of-the-art, yet open-source tools developed by popular companies and/or researchers in the field, such as OpenAI with GPT-2/3, Explosion with spaCy or StandfordNLP have helped saving much time and effort spent on a variety of NLP tasks. However, for non-English languages that are not spoken by a majority in the world (for example: Finnish, Swedish, etc) the resources might be limited. The NLP team at Hello Ebbot has been struggling with gathering and developing NLP models by ourselves. Understanding the difficulty, in this blog, we will share all open-source resources (including models, tools and datasets) that we found specifically serves Swedish - the language that our colleague Ebbot speaks mainly.
Lemmatization and POS tag
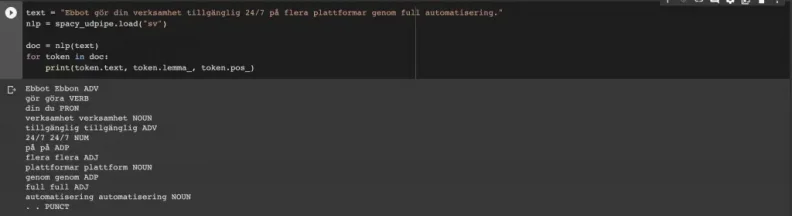
Lemmatization is the act of removing the endings of a word in order to return it to the base or dictionary form, which is usually known as "lemma". Sounds pretty cute, doesn't it! Lemmatization is considered to be a crucial task in pre-processing data for NLP tasks, especially when it comes to building chatbots, because it allows the machine to understand human language more accurately. For example, the lemma for "gör" (verb) is "göra" and "plattformar" (plural) is lemmatized to "plattform". Another important task in pre-processing is Part-of-Speech (POS) tagging. The name itself is explanatory. With this task, each word (and other token) will be assigned a part of speech; such as noun, verb, adjective, etc.
 Example of how to use the package
Example of how to use the package
Through Github, we found a reliable resource, a Python package which allows you to perform both lemmatization and POS tag for Swedish text in just a few lines of code. By wrapping UDPipe pre-trained models as a spaCy pipeline for 50+ languages, TakeLab opens a possibility to efficiently perform lemmatization and POS tagging. Here is the link to their Github repo.
NER datasets for spaCy training
SpaCy is one of the most popular libraries among NLP practitioners and researchers with pre-trained models for tagging, parsing and entity recognition supporting 15 languages at the time this blog is written. SpaCy also enables developers to train new model for unsupported languages, thus, Hello Ebbot's NLP team decided to try training a SpaCy NER for Swedish entities.
Finding solid datasets has always been a "journey" for us but luckily, we found a Swedish manually annotated corpus by a fellow NLP practitioner, Andreas Klintberg. The dataset was however adapted for CoreNLP (in .txt format) while SpaCy requires .json file as training data format. But don't you worry, we got you covered! If you head to this Medium post by DataTurks, you can find a script written for the conversion just as you need to train your own SpaCy NER.
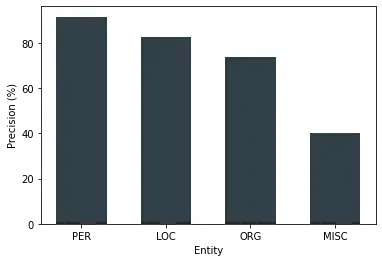
We also trained a NER model on this dataset, as well as Swedish fastText vectors. The result was 91.6% precision for PER (person), 82.8% for LOC (location), 73.9% for ORG (organization) and 40.3% for MISC (miscellaneous).
 Training results for the Swedish SpaCy NER
Training results for the Swedish SpaCy NER
The model works very well on people, cities, popular organizations and some street names in Sweden. However, we also noticed that it cannot detect some streets, for example: Fredriksdalsvägen. If you really want to have a SpaCy NER, we recommend converting these datasets from .csv to .json to have a larger corpus. Otherwise, please move on to the next section if you think using BERT is also fine 👇
Swedish BERT models
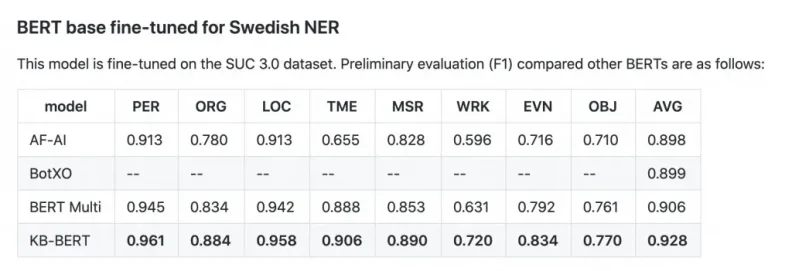
The National Library of Sweden (KBLab) generously shared not one, but three pre-trained language models, which was trained on a whopping amount of 15-20GB of text. Among these three, the most impressive one in our opinion must be "bert-base-swedish-cased-ner" due to its insane precision in matching entities. On KBLab's Github, you can find an evaluation on NER between this model and SweBERT by Arbetsförmedlingen (The Swedish Public Employment Service):
 Evaluation on different Swedish NER
Evaluation on different Swedish NER
Depending on the goals of your NLP tasks, you can either clone from their Github repo or for an easy instantiation, using the Huggingface pipeline is also another option. However, in order to achieve this precision, which is much higher compared to spaCy, you will have to sacrifice the speed, because BERT model takes far longer to train and even produce result. That's why we mentioned both of these two options, so you can choose models based on your development needs.
A little announcement:
We hope that this blog post is informative and resources found can at least help you save some time and effort in your NLP tasks. Just like every practitioner and researcher in the field, we would love to share our findings, or even researches and case studies. If you are also NLP enthusiasts like us, please keep an eye on our blog section for new content at least once per month!
References:
https://towardsdatascience.com/lemmatization-in-natural-language-processing-nlp-and-machine-learning-a4416f69a7b6

